Kiedy w 2008 roku wybuchła epidemia grypy (Google Flu Trends), ludzie, chcąc uzyskać więcej informacji na temat infekcji, wpisywali objawy swojej choroby w wyszukiwarce Google. Grypa postępowała, a lekarze nie mogli nad nią zapanować. Dzięki numerom IP, informacjom z systemu GPS i hasłom wyszukiwanym w przeglądarce, analitycy zdołali niemalże w czasie rzeczywistym obserwować jak postępuje grypa. To pozwoliło wdrożyć środki zapobiegające epidemii.
Wtedy po raz pierwszy zaobserwowano zależności między hasłami wyszukiwanymi w sieci, a rzeczywistymi zdarzeniami. Dane zaczęły być postrzegane jako źródło cennych informacji[1]. Dostrzegając ich potencjał, opracowywano pierwsze metodologie i systemy przetwarzania danych. Kolejnym etapem były bardziej złożone systemy, takie jak Internet Rzeczy czy składowanie danych w chmurze. Są one przejawami tzw. cyfrowej rewolucji, która jest jednym z najistotniejszych czynników, wpływających na stan dzisiejszej gospodarki.
Nowoczesna, cyfrowa technologia determinuje tzw. czwartą rewolucję przemysłową. W przypadku poprzednich rewolucji, czynnikiem przełomowym były odkrycia takie jak: mechanizacja przy użyciu wody i pary (rewolucja 1.0), elektryfikacja urządzeń i maszyn (rewolucja 2.0), wykorzystanie elektroniki dla automatyzacji produkcji (rewolucja 3.0). Obecna rewolucja 4.0 (lub też Przemysł 4.0) polega na integracji inteligentnych maszyn i systemów oraz optymalizacji produkcji przy wykorzystaniu Internetu Rzeczy. Ma ona w (niedalekiej) przyszłości doprowadzić m.in. do powstania inteligentnych fabryk (Smart factories), a w nieco odleglejszej – inteligentnych miast. Gdy już do tego dojdzie, konieczne będą głębokie zmiany w zarządzaniu, stosunkach pracy, bezpieczeństwie, produkcji i innych dziedzinach, które łączą się z przemysłem[2].
Od czasu epidemii grypy, zbierane i analizowane dane stopniowo przekształcały się w wielkie zbiory danych (tzw. big data). Dzisiaj trudno znaleźć obszar gospodarki, który by się z nimi nie łączył. Tematyka danych w gospodarce cyfrowej jest niezwykle istotna, ponieważ Przemysł 4.0 opiera się na umiejętnym ich wykorzystaniu i przetwarzaniu. Dlatego powstają dobre praktyki oraz regulacje, które starają się odpowiedzieć na wyzwania, przed którymi stoi przemysł. To dlatego m.in. Komisja Europejska stara się stworzyć regulacje i zasady funkcjonowania krajów członkowskich w dobie Przemysłu 4.0 opartego na danych.
Należy rozpatrzyć w jakich sektorach przemysłu będą wykorzystywane dane i jakie są konkretne technologiczne wyzwania. Na ile zmieni się rynek pracy i co musi ulec zmianie w systemie edukacji, aby odpowiadał na potrzeby cyfryzacji? Przed badaczami, podmiotami publicznymi i prywatnymi stoi dużo pytań. Wielkie zbiory danych i nowe technologie wciąż rozwijają się i pozostają dziedziną, w której dużo jest jeszcze do odkrycia.
Big Data
Mianem big data określamy wszystkie dane, które są zbierane, a następnie analizowane. Ponieważ danych jest coraz więcej, są one składowane w czasie rzeczywistym. Dzięki nim, firmy mogą personalizować reklamy, systemy mogą wcześnie wykrywać anomalie, a banki mogą decydować komu udzielić kredytu. Zgodnie z normą ISO/IEC 2382-1 dane to „reprezentacja informacji mająca interpretację, właściwą do komunikowania się, interpretacji lub przetwarzania” [3]. Dane mogą być produkowane przez osoby lub maszyny, często jako „produkt uboczny”. Dużymi zbiorami danych nazywamy takie dane, które są wytworzone z bardzo dużą prędkością z różnych źródeł i są niejednorodne. Ich obsługa wymaga nowych narzędzi i metod np. procesorów, oprogramowania i algorytmów.
Definicja big data przytaczana przez F. Cyprowskiego w Mini-podręczniku dla laików mówi, że są to zbiory danych generowanych automatycznie i z dużą częstotliwością, poddawane potem analizie i specjalnym sposobom przetwarzania. Odpowiednia analiza danych pozwala natomiast usprawnić funkcjonowanie firm, m.in. poprzez dostarczanie wiedzy o klientach. Celem big data jest uzyskanie większej efektywności w każdym aspekcie, którym zajmuje się dana firma – sprzedaży, consultingu, marketingu czy zarządzaniu[4]. Dane mogą być analizowane przez człowieka, który na ich podstawie wyciąga odpowiednie wnioski i stosuje je w praktyce, lub też przez algorytmy, które samodzielnie podejmują decyzje oraz proponują optymalne rozwiązania. Algorytmy są uczone wykrywania związków, a także zależności między danymi i stanowią główny element uczenia maszynowego znanego jako machine learning.
Big data definiowane są przez cztery kategorie: volume (ilość), velocity (szybkość), variety (różnorodność) i value (wartość), znane także jako 4V. Czasem możemy się spotkać z 3V, gdzie pod uwagę brane są tylko trzy pierwsze wartości, ponieważ czwarta – value – jest postrzegana jako stricte biznesowa.
- Volume – ilość danych. Zbiory danych są złożone z wielu małych danych, które mają niską gęstość zapisu[5]. Należą do nich np. posty na Twitterze, liczba kliknięć na stronie internetowej, ruch sieciowy i inne. Zadaniem big data jest przekonwertowanie danych o niskiej gęstości na dane o wysokiej gęstości, które będą miały istotną wartość.
- Velocity – szybkość danych. Niektóre z przedmiotów z kategorii Internet Rzeczy, które są powiązane ze zdrowiem lub z bezpieczeństwem człowieka, wymagają oceny i podjęcia akcji w czasie rzeczywistym. Dlatego tak ważna jest szybkość z jaką dane są bezpośrednio dostarczane do pamięci i zapisywane na dysku. Reszta urządzeń IoT również działa w czasie rzeczywistym lub prawie rzeczywistym. Na przykład aplikacja ecommerce (e-handel) stara się połączyć lokalizację urządzenia przenośnego ze spersonalizowanymi ofertami dla klienta. Cały czas wzrasta popularność aplikacji, co zwiększa ruch sieciowy, a tym samym zapotrzebowanie na jak najszybszy czas reakcji.
- Variety – różnorodność danych. Dane mogą być nieustrukturyzowane bądź prawie ustrukturyzowane (tekst, audio i wideo). Wymagają one przetworzenia, aby uzyskać ich sens oraz metadane. Ustrukturyzowane dane pochodzą z systemów przedsiębiorstw. Do nieustrukturyzowanych danych zaliczamy natomiast dokumenty Word, pliki PDF, e-maile, tweety, książki, zdjęcia, audio i wideo. Z kolei prawie ustrukturyzowane dane to na przykład pliki XML czy strony internetowe.
- Value – wartość danych. Dane mają istotną wartość, która ujawnia się w trakcie ich analizy. Istnieje wiele technik, które pozwalają uzyskać wartość danych: począwszy od odkrywania preferencji czy uczuć konsumenta, a skończywszy na tworzeniu oferty dostosowanej do lokalizacji użytkownika. Gdy danych było już dużo, ich cena znacznie spadła, co umożliwiło przełom technologiczny. Znalezienie wartości danych wymaga nowych odkryć w procesach przetwarzania danych. Obecnie prawdziwym wyzwaniem dla analityków jest nauczenie się zadawania właściwych pytań, rozpoznawanie prawidłowości, świadome szukanie zależności oraz przewidywanie zachowań [6].
Istotną cechą danych jest to, że się nie zużywają. Mogą być wielokrotnie analizowane i używane do różnych celów. Dlatego otrzymały miano „rewolucyjnego bogactwa”[7]. Zaletą wielkich zbiorów danych jest także ich powszechna i łatwa dostępność, niewysoki koszt utrzymania i składowania oraz to, że dzięki nim mogą być realizowane różne badania[8].
Według Eurostatu[9] dane we współczesnej gospodarce dzielone są na trzy grupy w zależności od źródła, z którego pochodzą:
- Dane z sieci społecznościowych (obrazy, wideo, wyszukiwania, wiadomości, komentarze i inne).
- Dane ustrukturyzowane pochodzące z systemów informatycznych (dane podmiotów publicznych, przedsiębiorstw itp.).
- Dane ustrukturyzowane pochodzące z czujników Internetu Rzeczy (automatyka przemysłowa, zdjęcia satelitarne, lokalizacja, automatyka domowa)[10].
Istnieją też inne podziały danych np. na poziom ich jawności, osobowe i nieosobowe, zawierające tajemnice objęte ograniczeniem jawności itp. Grupy danych przenikają się, a ich wpływ na społeczeństwo i gospodarkę jest coraz większy. Mimo to kwestia praw autorskich wciąż jest niejasna. Trwa dyskusja na temat tego, czy powinno się uznać je za dobro wspólne. To tworzy ideę otwartych danych (ponowne wykorzystanie danych publicznych i przemysłowych), która ma pozwolić na budowanie gospodarki opartej na danych[11].
Internet Rzeczy (IoT)
Wielkie zbiory danych stanowią bazę funkcjonowania Internetu Reczy (IoT). Dzięki IoT przedmioty codziennego użytku zyskały swoistą „inteligencję”, komunikując się ze sobą lub podpowiadając właścicielowi co powinien zrobić w danej sytuacji. Lodówki sugerują co musimy kupić, pralka podpowiada, że należy zrobić pranie, a opaska na rękę mierzy jakość snu. To wszystko sprawia, że zmienia się nie tylko życie użytkowników takich sprzętów, ale także podejście do technologii, a tym samym całej gospodarki.
Przemysł 4.0 to przede wszystkim przejście do modelu, w którym wszystkie działania produkcyjne są nadzorowane i zarządzane cyfrowo. Stopniowo następuje fuzja świata fizycznego i wirtualnego, którą umożliwia system CPS (cyber-physical system). Inteligentna fabryka w gospodarce cyfrowej będzie zawierała systemy CPS komunikujące się z IoT, co pomoże ludziom i maszynom w wypełnianiu swoich zadań. System CPS jest definiowany jako technologia transformatywna do zarządzania połączonymi systemami między ich komputerowymi możliwościami i kapitałem fizycznym.
CPS ma dwie ważne cechy: zaawanasowaną łączność, która zapewnia pozyskiwanie danych w czasie rzeczywistym i informację zwrotną z cyberprzestrzeni, a także inteligentne zarządzanie danymi, czyli obliczeniowe i analityczne możliwości, które budują cyberprzestrzeń[12]. Technologię internetową dzielimy na[13]:
- Internet Rzeczy (IoT) – komunikowanie się inteligentnych systemów przy użyciu adresów IP. Każdy przedmiot musi być wyposażony w unikalny adres IP.
- Internet Usług (IoS) – usługi takie jak architektura zorientowana na usługi (SOA).
- Internet Danych (IoD) – składowanie i przesyłanie dużej ilości danych, wprowadzanie nowych metodologii do interpretacji masowych danych[14].
Systemy CPS, w kontekście wytwarzania i automatyzacji, mają być stosowane na różnych etapach produkcji, takich jak symulacja, projektowanie, kontrolowanie i weryfikacja. Systemy te będą skomunikowane, rozpowszechnione i skoordynowane. Dzięki temu rozwiązaniu, które składa się na inteligentne prognozy oraz diagnozy z zastosowaniem big data z różnych maszyn i sensorów, w wytwórstwie może polepszyć się jakość i produktywność. CPS połączy postępy, które zostaną osiągnięte dzięki dużym systemom komputerowym podczas planowania, modelowania i prognozowania przy wykorzystaniu mocy danych, które zostały wygenerowane przy procesach wytwórczych przez dużą ilość małych urządzeń.
Te wszystkie nowe technologie wpływają na szybkie zmiany w przemyśle. Na przykład IoT stanowi solidny fundament dla cyfrowych technologii do zmiany wytwórstwa. Analizy big data polepszają wydajność produkcji poprzez udoskonalanie usług, redukując koszty energii i zwiększając jakość produkcji. Składując i analizując dane z różnych źródeł, takich jak systemy zarządzania klientami, managerowie mogą podejmować lepsze decyzje w czasie rzeczywistym[15].
W Przemyśle 4.0 firmy mogą być zintegrowane horyzontalnie i wertykalnie, przez co dane wraz z informacjami mogą być wymieniane między firmami, a także poza ich murami. Przedsiębiorstwa zmierzą się więc m.in. z następującymi wyzwaniami:
- Chmura obliczeniowa – umożliwia przetwarzanie dużej ilości danych oraz szerokie symulacje z różnymi aspektami operacji.
- Globalna baza danych – wymiana danych/informacji między logistycznymi i produkcyjnymi centrami firm.
- Automatyzacja – automatyczne systemy łączą świat fizyczny ze środowiskiem wirtualnym informacji (często cyfrowym) przez integrację jednostek przetwarzania z czujnikami.
- Sieci – TCP/IP, najczęstszy protokół internetowy do podłączenia dużej liczby urządzeń[16].
Sztuczna Inteligencja
Jak podaje raport Forbes: „Nie ma jednej, powszechnie akceptowanej definicji sztucznej inteligencji. Termin ten zwykle odnosi się do zdolności maszyn do uczenia się, podejmowania decyzji i wykazywania się inteligencją zbliżoną do ludzkiej – na przykład zdolnością do samodzielnego rozwiązywania problemu bez korzystania z wcześniej zaprogramowanego przez człowieka algorytmu”[17]. Takie działania są możliwe w uczeniu maszynowym i zastosowaniu algorytmów, które na bazie wielkich zbiorów danych będą znajdowały zależności, usprawniając w ten sposób produkcję. Sztuczna inteligencja to dziedzina powiązana z big data, która dzięki rozwiniętym algorytmom będzie zmieniała gospodarkę. Sprawi, że produkcja będzie przebiegała szybciej, sprawniej, ewentualne błędy będą wykrywane w porę, aby zminimalizować straty, a oferta produktu będzie dostosowywana do indywidualnych potrzeb klientów[18].
Według planu działań, sporządzonego przez Ministerstwo Cyfryzacji wraz z ekspertami, do głównych sektorów gospodarki, w których powinna być wdrożona sztuczna inteligencja należą[19]:
- Przemysł – redukcja ilości odpadów, zwiększenie efektywności zakładów przemysłowych, redukcja błędów łańcucha dostaw, projektowanie maszyn oraz wykrywanie przyczyn ich awarii.
- Medycyna – wczesne wykrywanie chorób na podstawie badań nielaboratoryjnych, wstępna diagnoza pacjenta na poziomie internistycznym, dobór leków.
- Transport i logistyka – optymalizacja załadunku i tras samochodów, automatyzacja samochodów ciężarowych, przewidywanie opóźnień w transporcie, kierowanie ruchem w miastach, roboty zarządzające magazynami.
- Rolnictwo – przewidywanie plonów na podstawie analizy zdjęć satelitarnych, optymalizacja zasiewów, selektywne opryskiwanie wybranych roślin zamiast całych pól oraz wczesne wykrywanie chorób plonów, autonomiczne maszyny rolnicze, roboty odstraszające ptaki.
- Energetyka – zarządzanie obciążeniem sieci, konserwacja zapobiegawcza, wykrywanie kradzieży prądu.
- Administracja państwowa – wykrywanie malwersacji podatkowych i oszustw płatniczych, nowe kanały kontaktu urzędów z obywatelami oraz interaktywna obsługa obywateli, identyfikacja fałszerstw w dokumentach i nieautoryzowanego dostępu do systemów elektronicznych.
- Handel i marketing – wykrywanie twarzy i emocji klientów, automatyczne tworzenie opisów produktów, systemy rekomendacji, inteligentne lustra i przymierzalnie.
- Budownictwo – projektowanie budynków biurowych pod potrzeby pracowników, optymalizacja zużycia energii w budynkach oraz wykorzystania przestrzeni, systemy wykrywania twarzy, wezwanie ochrony po wykryciu próby włamania.
- Cyberbezpieczeństwo – identyfikacja incydentów, profilowanie aplikacji sieciowych i użytkowników w celu wykrywania anomalii, identyfikacja nadchodzących ataków.
Warto też zauważyć, że rozwój sztucznej inteligencji wymaga pojawienia się nowych zawodów, w których potrzebni są specjaliści związani z nowymi technologiami. W książce Martin Forda Świt robotów czytamy: „Badania przeprowadzone w 2013 roku przez Carla Benedikta Freya i Michaela A. Osborne’a z Uniwersytetu Oksfordzkiego wykazały, że zawody stanowiące niemal połowę wszystkich stanowisk w Stanach Zjednoczonych mogą zostać zautomatyzowane w ciągu najbliższych 20 lat” [20].
W odpowiedzi na rozwój nowych technologii, rynek pracy także przechodzi nieodwracalną rewolucję. Aby sprostać nowym wymaganiom, będą potrzebni specjaliści z dziedziny big data, przetwarzania języka naturalnego, robotyki, uczenia maszynowego, sztucznej inteligencji, cyberbezpieczeństwa czy Internetu Rzeczy. Według firmy KPMG w obszarze pracy ze sztuczną inteligencją pojawią się takie zawody jak:
- Architekt sztucznej inteligencji – ekspert zajmujący się procesami biznesowymi. Bada gdzie warto wdrożyć SI. Do jego zadań należy kontrolowanie wydajności i utrzymywanie modelu SI w miarę upływu czasu.
- Product Manager SI – blisko współpracuje z architektem SI. Łączy różne zespoły, aby zostały wdrożone najlepsze rozwiązania dla firmy. Współpracuje ze wszystkimi zespołami w celu identyfikacji koniecznych zmian w organizacji, aby działania człowieka i maszyny były optymalne.
- Data Scientist – specjalista zajmujący się czyszczeniem danych, projektowaniem i zastosowaniem algorytmów w celu uzyskania analiz.
- Inżynier oprogramowania – ściśle współpracuje z data scientist, aby wprowadzić sztuczną inteligencję w fazę produkcji, łącząc wiedzę biznesową z głębokim zrozumieniem działania SI.
- Etyk sztucznej inteligencji – ponieważ etyczne i społeczne implikacje SI nadal nie są do końca jasne, firmy będą potrzebowały tworzenia ram sztucznej inteligencji, które będą podtrzymywały standardy firmy i kodeksy etyczne[21].
Martin Ford w swojej książce Świt robotów zauważa, że kiedy zawody wymagające wysokich kwalifikacji zostaną poddane automatyzacji, nastanie czas elit finansowych, których wpływy będą jeszcze większe niż obecnie. Grupą, która na tym ucierpi, będzie najniższa klasa społeczna. Wszechobecny kapitalizm dosłownie pożre najuboższych, którzy nie będą w stanie konkurować na rynku pracy z maszynami[22].
Światowe Forum Ekonomiczne w 2018 roku przygotowało raport dotyczący pracy przyszłości[23]. Jedną z kwestii poruszonych w raporcie jest liczba godzin pracy człowieka i maszyny. Porównano pracę wykonaną w roku 2018 i prognozami na rok 2022. Przewiduje się, że udział maszyny w pracy będzie stopniowo rósł.
Wykres 1. Stosunek człowieka i maszyny do godzin pracy 2018 vs. 2022 (przewidywany)
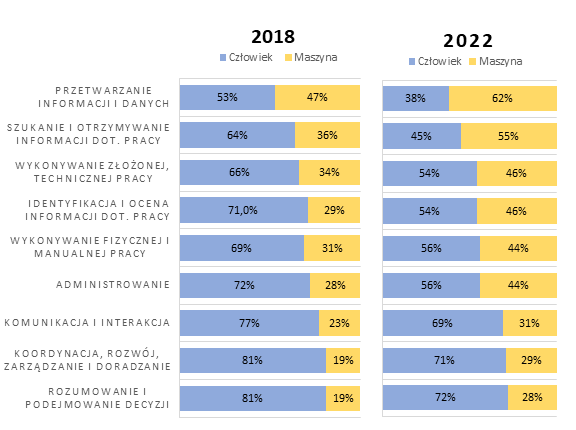
Źródło: http://www3.weforum.org/docs/WEF_Future_of_Jobs_2018.pdf
Według raportu w ciągu najbliższych trzech lat sztuczna inteligencja będzie wykonywać ponad połowę pracy w dziedzinach takich jak: przetwarzanie informacji i danych (o 24 punkty procentowe wyższy udział maszyny), szukanie i otrzymywanie informacji dotyczących pracy (o 10 punktów procentowych wyższy udział maszyny). Powodem jest stałe udoskonalanie algorytmów oraz fakt, że dzięki wielkim zbiorom danych, uczenie maszynowe może rozwijać się w sposób nienadzorowany. Przetwarzanie danych oraz wyszukiwanie informacji nie są procesami tak skomplikowanymi, jak podejmowanie decyzji czy zarządzanie. Oczywiście roboty takie jak Pepper[24], które uczą się rozpoznawać emocje i reagować na nie, a także wykonywać prace administracyjne, wchodzą na salony różnych firm[25]. Jednak praca międzyludzka jest złożonym procesem, który wymaga nie tylko umiejętności i kwalifikacji, ale uwzględnia także emocje, stosunki współpracowników czy uczucia – a w tych aspektach maszyna wciąż nie dorównuje człowiekowi.
Podsumowanie
- Big data, sztuczna inteligencja, Internet Rzeczy i uczenie maszynowe doprowadziły do czwartej rewolucji przemysłowej.
- Przemysł 4.0 to otwarcie danych, ujednolicenie systemów, zastąpienie człowieka przez maszyny.
- Do wyzwań, przed którymi będą stali przedsiębiorcy w Przemyśle 4.0, należą: chmura obliczeniowa, globalna baza danych, automatyzacja, sieci.
- W związku z rozwojem nowoczesnych technologii i rosnącym wpływem big data, pojawią się nowe zawody związane z inżynierią danych.
[1] V.Mayer-Schönberger, K.Cukier, Big Data, Rewolucja, która zmieni nasze myślenie, pracę i życie, Wydawnictwo MT Biznes, Warszawa 2014, s.222
[2] S.Łobejko, Strategie cyfryzacji przedsiębiorstw, [w:] Innowacje w zarządzaniu i inżynierii produkcji, Tom II, Oficyna Wydawnicza Polskiego Towarzystwa Zarządzania Produkcją, Opole 2018, s. 641-644
[3] Komisja Europejska, Komunikat Komisji do Parlamentu Europejskiego, Rady, Europejskiego Komitetu Ekonomiczno-Społecznego i Komitetu Regionów, Ku gospodarce opartej na danych, 02.07.2014, s.4
[4] F.Cyprowski, Big Data. Mini-podręcznik dla laików, Instytut Badań Rynkowych i Społecznych, 2014, s.3
[5] Gęstość zapisu jest miarą ilości informacji (wyrażonej w liczbie bitów), którą można zapisać na określonej przestrzeni. Niska gęstość zapisu oznacza, że możliwe jest zapisanie mniejszej ilości danych w ramach tej samej dostępnej przestrzeni fizycznej.
[6] Oracle, An Entreprise Architect’s Guide to Big Data, https://www.oracle.com/technetwork/topics/entarch/articles/oea-big-data-guide-1522052.pdf
[7] Autorem tego miana jest Alvin Toffler, który napisał książkę o tym samym tytule.
[8] Ministerstwo Cyfryzacji, Przemysł +, Gospodarka oparta na danych, s.4
[9] M.Beręsewicz, R.Lehtonen, F.Reis i inni, Eurostat, An overview of methods for treating selectivity in big data sources, 2018, s.20
[10] Ibidem., s. 9
[11] Ibidem., s. 8-9
[12] S.Łobejko, Op.cit., s.643-644
[13] Podział dokonany przez I.R. Anderl, Industrie 4.0 – Advanced Engineering of Smart Products and Smart Production, Technological Innovations in the Product Development, 19th International Seminar on High Technology, Piracicaba, Brasil, 2014, s.1-14, [w:] L.Wang, G.Wang, Big Data in Cyber-Physical Systems, Digital Manufacturing and Industry 4.0, 2016, s.1-3
[14] L.Wang, G.Wang, Big Data in Cyber-Physical Systems, Digital Manufacturing and Industry 4.0, 2016, s.1-3
[15] Ibidem.
[16] Ibidem.
[17] McKinsey&Company, Forbes, Rewolucja AI, jak sztuczna inteligencja zmieni biznes w Polsce, 2017 s. 8
[18] Ministerstwo Rozwoju, Departament Strategii Rozwoju, Strategia na rzecz odpowiedzialnego rozwoju do roku 2020 (z perspektywą do 2030 r.), Warszawa 2017, s. 9
[19] Ministerstwo Cyfryzacji, Założenia do strategii AI w Polsce – Plan działań Ministerstwa Cyfryzacji, 09.11.2018, s.44-46. Plan powstał pod koniec 2018r. Dokument podsumowujący jest zestawieniem prac Grupy 1 ds. Gospodarki opartej na danych. Zagadnienia wskazane i przeanalizowane zostały podzielone na trzy perspektywy: krótkoterminową (okres do 2 lat), średnioterminową (do 6 lat) i długoterminową (do 12lat, a więc do 2030r.). Analizy dokonano na podstawie ankiet rozesłanych do wszystkich uczestników grupy 1 oraz na podstawie intensywnych dyskusji i wymianie korespondencji drogą mailową.
[20] M. Ford, Świt robotów, Cdp.pl, Warszawa 2016, s.73
[21] KPMG, Top 5 AI hires companies need to succeed in 2019, https://info.kpmg.us/news-perspectives/technology-innovation/top-5-ai-hires-companies-need-to-succeed-in-2019.html
[22] Ibidem.
[23] World Economic Forum, Insight Report, The Future of Jobs Report 2018, s.11
[24] Robot zatrudniony na recepcji w firmie Weegree w Opolu.
[25] https://www.softbankrobotics.com/emea/en/pepper, 22.02.2019